
Mastering Distributed Transactions: Ensuring One-Time Email Delivery to Users
Introduction
In today's digital landscape, email communication remains a vital channel for businesses to engage with their users. When sending transactional emails, such as account confirmations or password resets, it is crucial to ensure that each email is delivered exactly once. However, in a distributed system where multiple services and components are involved, achieving reliable one-time email delivery can be challenging. In this blog post, we will explore the concept of distributed transactions and present strategies for guaranteeing one-time email delivery to users.
Understanding Distributed Transactions
Transactions that span over multiple physical systems or computers over the network, are simply termed Distributed Transactions. In the world of microservices, a transaction is now distributed to multiple services that are called in a sequence to complete the entire transaction. For detailed explanation refer Handling Distributed Transactions in the Microservice world.
Distributed transactions are a means of managing consistency across multiple systems or services. They allow multiple operations across different resources to be treated as a single transaction, ensuring that either all operations succeed or none of them do. In the context of email delivery, distributed transactions can help us guarantee the atomicity of sending an email, ensuring that it is either delivered exactly once or not at all.
Usecase
We wanted to send customised emails to our customers stating their past one month device usage statistics. SES was chosen as a platform for sending emails. A serverless architecture to implement this system was more operationally lighter.
Challenges in One-Time Email Delivery
Several challenges arise when attempting to ensure one-time email delivery in a distributed system:
- Service failures: Services involved in the email delivery process may experience failures, leading to duplicate emails or email loss.
- Network issues: Transient network failures can result in email delivery inconsistencies.
- Asynchronous nature: Email delivery is typically asynchronous, making it harder to guarantee one-time delivery.
How wouldd it affect our customers
- Suppose we are sending 100 emails on the 1st day of every month. Here the simple basic code will run loop for 100 times sending one email in each iteration to a specific address.
- Suppose in between, the code fails and we restart. Here the code will start executing again from the initial customer and start sending mails.
- The problem here is if the code fails at 55 iterations of the loop then after restarting the code will send those 55 mails again and then remaining.
- If errors are not handled properly, this process can continue indefinitely. It will end up sending duplicate mails to the same customer again and again.
- And honestly no customer will want spams in his inbox.
- So that’s why the system has to be idempotent.
Strategies for Ensuring One-Time Email Delivery
To address the challenges mentioned above and achieve reliable one-time email delivery, consider the following strategies:
-
Idempotency: Make the email delivery process idempotent, meaning that multiple delivery attempts have the same effect as a single attempt. Assign a unique identifier to each email, and track and store the delivery status for each identifier. This allows you to handle duplicate delivery attempts and prevent multiple emails from being sent.
-
Distributed Locking: Implement a distributed locking mechanism to ensure that only one instance of the email delivery service can process a specific email at a time. Distributed lock managers like Apache ZooKeeper or Redis can help you achieve this by providing distributed locks that allow exclusive access to a resource.
-
Transactional Messaging: Use a message queue or a pub-sub system to decouple the email delivery process. Each email sending request can be placed in a message queue, and a separate worker service can process these messages. By leveraging transactional messaging systems like Apache Kafka or AWS SQS, you can guarantee that messages are processed exactly once.
-
Retry Mechanisms: Implement a retry mechanism for failed email delivery attempts. If an email fails to send due to a service or network issue, retry the delivery process after a certain interval. Apply exponential backoff strategies to prevent overwhelming the system with retries.
-
Dead Letter Queue: Set up a dead letter queue to capture failed delivery attempts or emails that could not be sent due to invalid recipient addresses. Analyze the content of the dead letter queue periodically to identify and resolve any potential issues.
-
Monitoring and Alerting: Implement robust monitoring and alerting mechanisms to detect anomalies and failures in the email delivery process. Use tools like Prometheus, Grafana, or AWS CloudWatch to track key metrics, set up alarms, and receive notifications in case of failures.
Solution
Approach 1 - Conventional
We can use a script to run a loop over all emails andd send the emails to specific addresses using aws ses api.
Drawbacks
- The problem here was that the system was not idempotent. Duplicates mails are sent if lambda fails and restarts again.
- The system is not scalable as the lambda also has restrictions like timeouts, limited retries.
- Error Handling is poor as a single error can fail lambda and have to retry the entire procedure
Approach 2 - Using Simple Queue service to handle the atomicity of distributed transaction
- As seen in the architecture below, our first lambda function builds emails and sends them to the email queue which is basically a simple queue service. These messages added to the queue are basically email data and details. The ‘sendEmail’ Lambda function processes the messages in the queue and sends emails using AWS SES.
- Here the probability of scalability is solved as the sqs scales itself and creates multiple instances of sendEmail function.
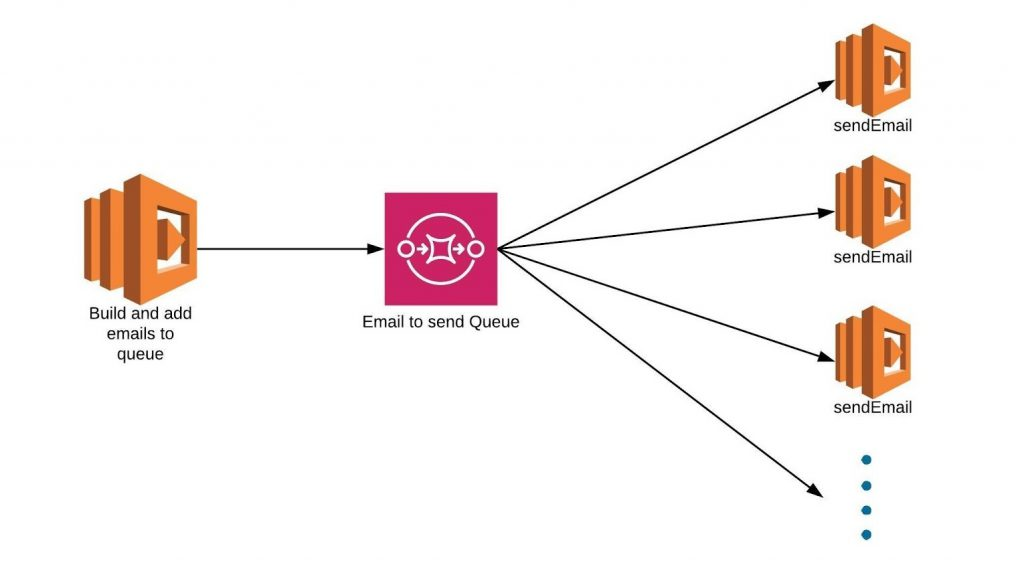
Drawbacks
The problem here was about deduplication. The SQS doesn’t have a mechanism to reject duplicates and also does not allow to create customized identifiers for message.Hence if the main lambda fails then after restart it will start adding the duplicates to the queue. Hence the system was not Idempotent.
Approach 3 - Using DynamoDB streams to handle atomicity of distributed transaction
As seen in the architecture below, Our first lambda builds emails and updates the DynamoDB table.Here DynamoDB have streams enabled which triggers the sendEmail lambda function on every row update.
Note: Here the sendEmail processes the single row update and sends email accordingly.
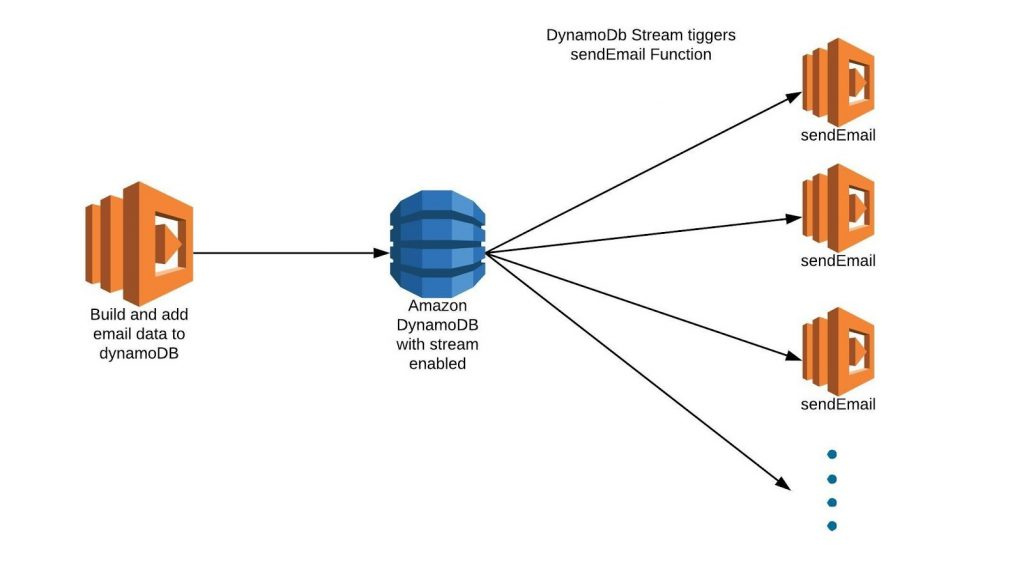
- Here DynamoDb streams create multiple instances of sendEmail as per the number of concurrent updates.
- Here the problem of scalability is solved and if a sendEmail lambda instance fails then it only fails one email and others are not affected.
- Here the problem of duplication also solves as we can make customized keys for every email and also search for past execution.
Drawbacks
- Lambda function comes with restrictions on the number of retries and back-off rate. Lambda only allows maximum 2 retries. So if we configure Dead Letter Queue and rerun from that then there is a possibility that it can lead to infinite retries.
- AWS SES have its own sending limits. These limits are Sending quota—the maximum number of recipients that you can send email to in a 24-hour period and Maximum send rate—the maximum number of recipients that you can send email per second. If the send rate crosses the limit then SES throws error(‘Throttling’) and to tackle that error we need a proper exponential back-off in retries.
- You need to customize the retries and back-off rate. And the solution for this comes out of the box in AWS Step Functions
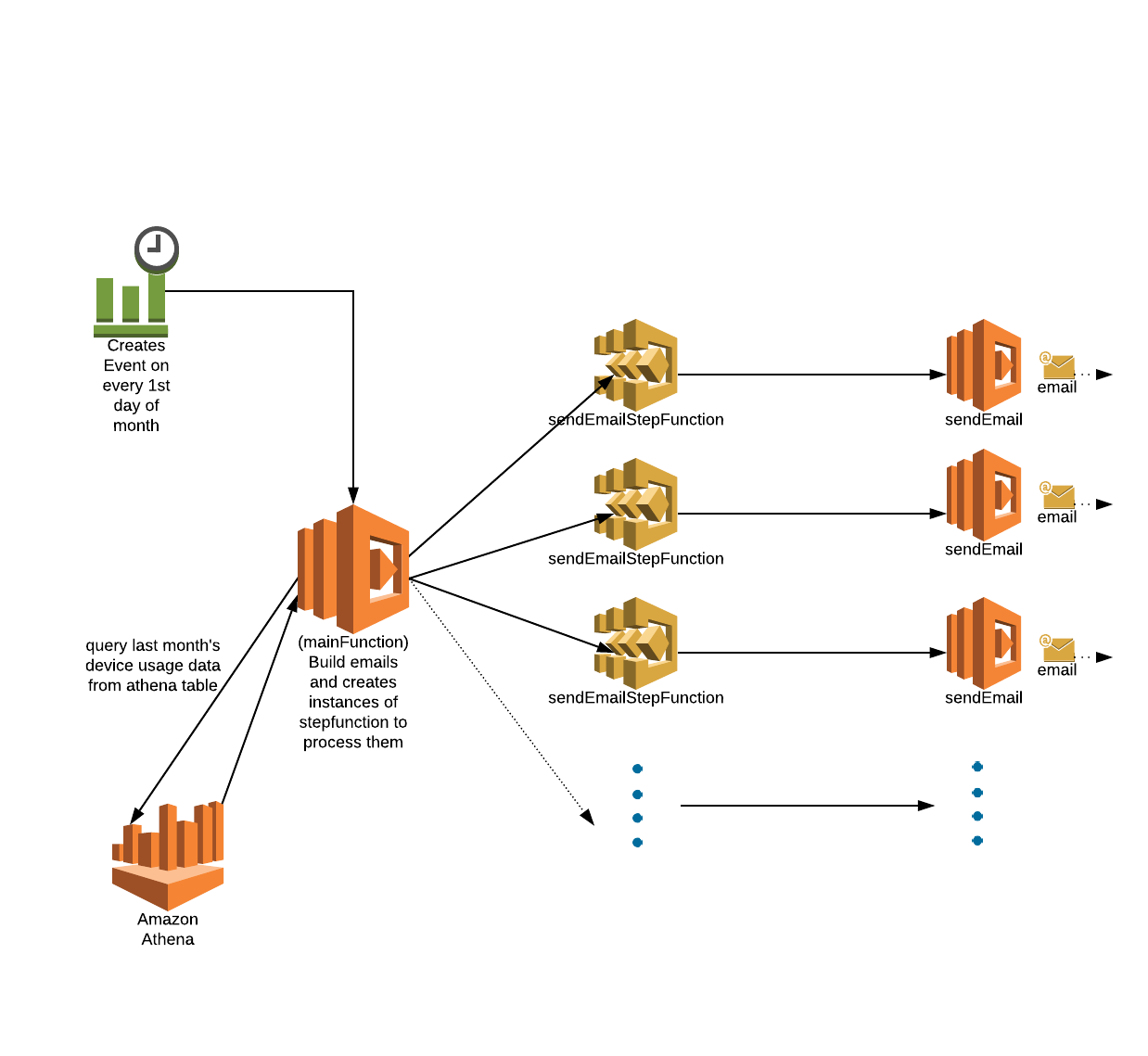
Approach 4 - Use a workflow orchestration system - Step Functions
To solve the various problems of distributed transaction, we came up with the final architecture using AWS Step Functions
What are Step Functions?
AWS Step Functions lets you coordinate multiple AWS services into serverless workflows.Workflow into a state machine diagram that is easy to understand, easy to explain to others, and easy to change.
Step Functions automatically triggers and tracks each step, and retries when there are errors, so your application executes in order and as expected.
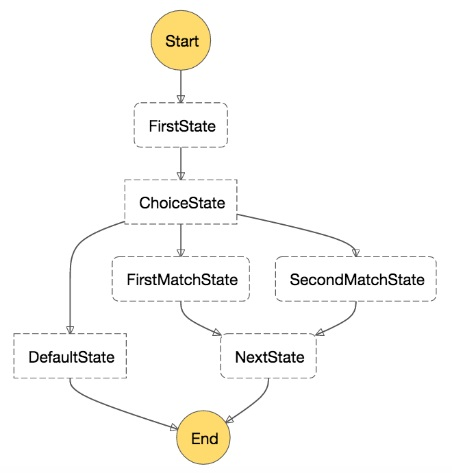
Example of a sample workflow on step Functions
Our solution
Step Function definition
{
"Comment": "sending Email",
"StartAt": "sendEmail",
"States": {
"sendEmail": {
"Type": "Task",
"Resource": "paste the sendEmail lambda ARN",
"End": true
}
}
}
Step Function visualization
Here we can define error states in definition and define retry count, retry interval and back-off rate for each specific error.
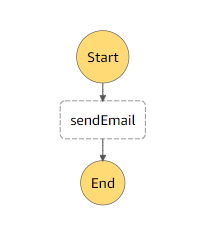
Lambda function ‘sendEmail’
This lambda function runs on the trigger of ‘sendEmailStepFunction’ execution. Here it uses AWS SES api to send a single mail as per the event created by sendEmailStepFunction. The event contains the email data.
Sample code for sending email using Simple email service
const params = {
Source: "[email protected]",
Template: "emailTemplate",
Destination: {
ToAddresses: [emailId]
},
TemplateData: "{\"usage\":\"99\”}”
};
//send email
var sendTemplatedEmailPromise = (new aws.SES()).ses.sendTemplatedEmail(params).promise();
await sendTemplatedEmailPromise;
Lambda function ‘mainFunction’
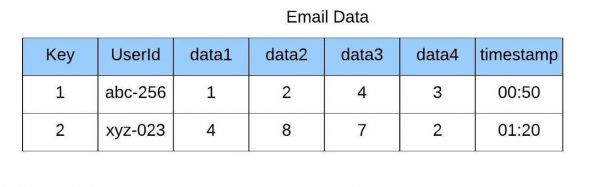
The mainFunction extracts the data from the athena table using SQL query. The data obtained is in the form of JSON format as shown below. For e ach user ID, the system creates email data and calls the StepFunction ‘sendEmailStepfunction’, which triggers the ‘sendEmail’ function with the event as input. The ‘sendEmail’ function then sends the email using AWS SES. AWS creates a new instance of the ‘sendEmailStepfunction’ for every execution.
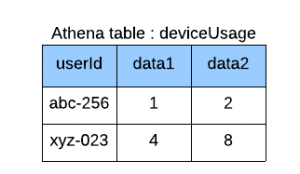
athenaQueryOutput = {
Items:
[{ userid: 'abc-256', data1: '1', data2: '2' },
{ userid: 'xyz-023', data1: '4', data2: '8' }],
Data Scanned In MB: 0,
QueryCostInUSD: 0.0000,
EngineExecutionTimeInMillis: 0,
Count: 0,
QueryExecutionId: 'testExecutionID',
S3 Location:
'Test_s3_location'
}
Solution to previous example
We took an example of sending 100 emails on the 1st day of every month. Here, we will create 100 instances of sendEmailStepFunction, and each instance will be responsible for delivering a respective email. Suppose in between, the mainFunction fails and restarts. Here the function starts executing step functions again from first.
So how to prevent duplication?
Here step function’s ‘name’(params.name) has to be always unique. So if there is a re-execution of step function then it will return error ‘ExecutionAlreadyExists’ and hence we can skip that and move ahead. That’s how we can stop duplication and make system Idempotent.
Cons of using AWS Step Functions
AWS Step Functions takes each execution and each retry as a separate state transition. AWS charge per each state transition hence they can be expensive. So for large scale we can use open source system like Apache Airflow.=
Conclusion
Ensuring one-time email delivery in a distributed system is a critical aspect of maintaining a reliable and consistent user experience. By understanding distributed transactions and employing strategies such as idempotency, distributed locking, transactional messaging, retries, dead letter queues, and monitoring, you can achieve a robust and fault-tolerant email delivery system. Implementing these strategies will help you maintain the integrity of your communication channels and ensure that users receive transactional emails accurately and only once.